Was ist Data-Mining?
Was ist Data-Mining?
Der Begriff Data-Mining wird in der Praxis sehr häufig unterschiedlich verwendet. Geprägt wurde er aus dem Anspruch in großen Datenmengen automatisiert nach neuen Erkentnissen zu suchen. Er bezeichnet oftmals auch nur die Techniken, die bei der Datenanalyse zum Einsatz kommen und wird daher auch für die Kennzeichnung von Data-Mining-Software verwendet.
Korrekter ist allerdings die Betrachtung eines gesamten Prozesses:
Data Mining ist der Prozeß, automatisch, vorher unbekannte, statistisch korrekte, interessante und interpretierbare Zusammenhänge in großen Datenmengen zu finden und diese für wichtige Unternehmensentscheidungen zu verwenden.
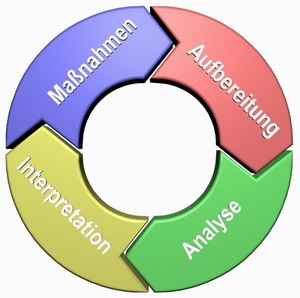
Data-Mining-Prozeß
Der Data-Mining-Prozess besteht aus einer wiederkehrenden zyklischen Abfolge folgender Schritte:
- Die Datenaufbereitung befasst sich mit der Sichtung, Aggregation und Aufbereitung von Daten für die Analyse. Eine sorgfältige Aufbereitung der Daten ist absolute Voraussetzung für die Möglichkeit aussagekräftige Ergebnisse bei der Datenanalyse zu erhalten.
- Bei der Datenanalyse werden u.a. die Techniken der Statistik und des Maschinellen Lernens für die Erkennung und für die Extraktion von Mustern und Beziehungen aus den Daten eingesetzt.
- Nach Abschluss der Analyse werden die Ergebnisse unter enger Beteiligung der Fachkompetenz des Unternehmens einer Interpretation unterzogen. Die Auswertung umfasst u.a. die Extraktion der für das Unternehmensziel verwendbaren Erkenntnisse.
- Aus den Ergebnissen der Interpretation werden Maßnahmen abgeleitet, die eine praxisnahe Umsetzung der Data-Mining-Ergebnisse darstellen. Diese Maßnahmen haben wieder direkten Einfluß auf die zuvor berücksichtigten Daten und stellen damit die Quelle für ein Feedback in diesen Zyklus dar. Die erweiterten Daten sind wiederum Basis für die erneute Datenaufbereitung und der Data-Minig-Zyklus beginnt erneut.